





The enterprise analytics industry has spent two years watching agentic AI demos succeed. Every major BI vendor has one. Most enterprises have run one. The story that does not make the conference keynote is what happens next: why so few of those demos become production deployments, and why the organizations that shut them down rarely understand the actual cause of failure. Gartner predicts that more than 40% of agentic AI projects will be canceled by end of 2027. Most of those cancellations will not happen because the technology failed. They will happen because the enterprise environment underneath it was not ready.
The Gap Between a Demo and a Deployment
An agentic analytics demo proves one thing: given a clean dataset and a well-scoped prompt, the AI model can return a structured output. That is a real capability, but it is not what production deployment requires.
A production deployment has to do something considerably harder. It has to produce outputs that are consistently trusted by the people who use them to make real decisions: not once, with a curated dataset, in a controlled environment, but reliably, across the full complexity of an enterprise analytics estate, against questions that were not in the demo script, grounded in business context the team was not aware of during the pilot, and with every action auditable by risk and compliance stakeholders who were not in the room.
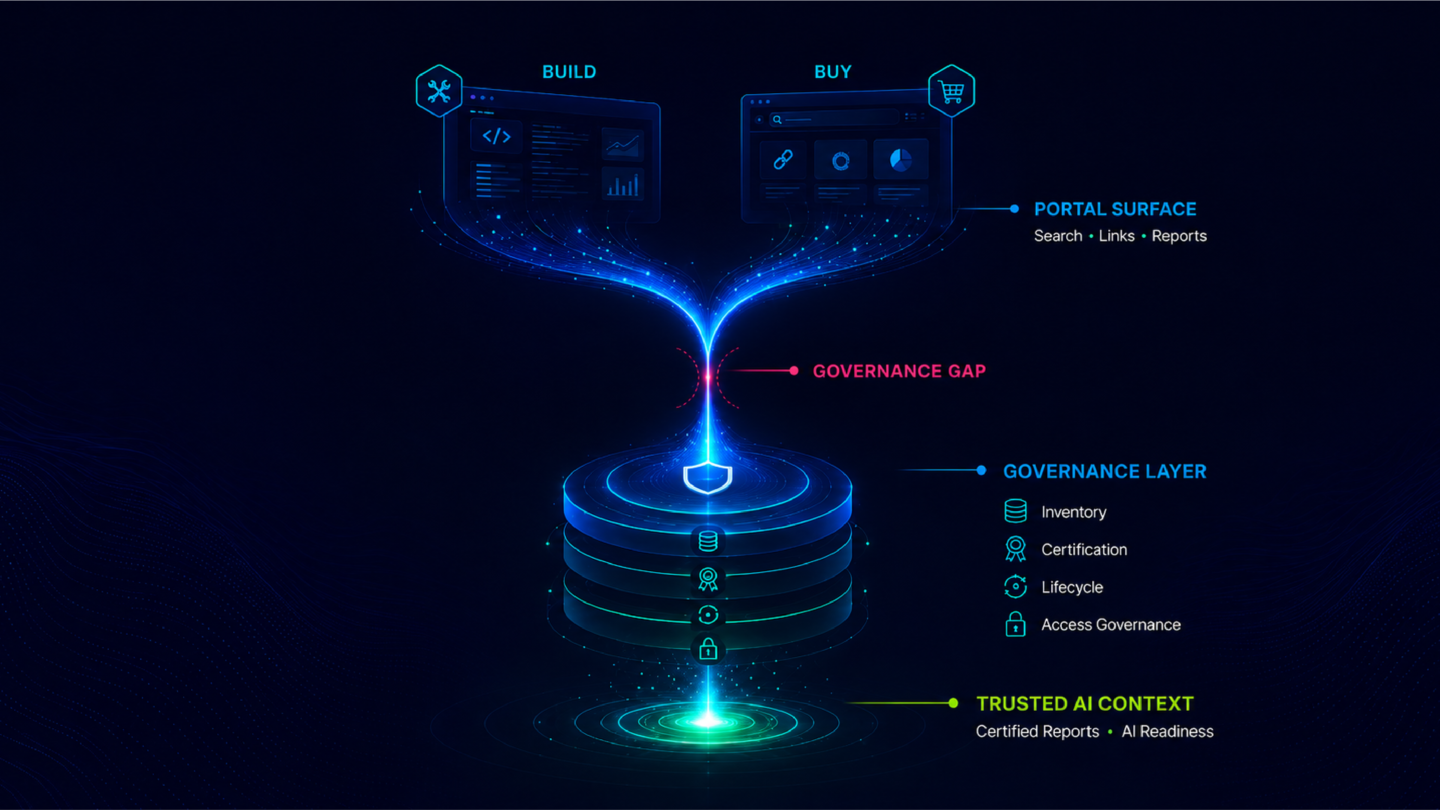
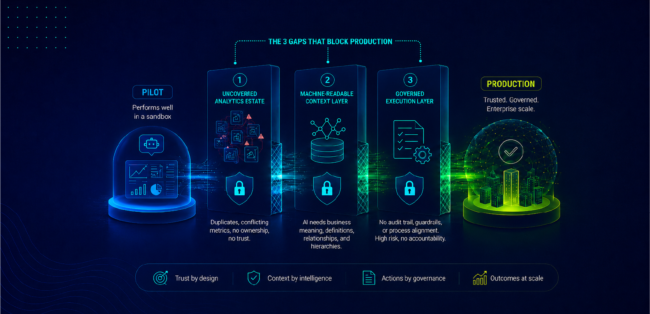
The gap between those two things is where most pilots stall. It is not usually a model problem, a data pipeline problem, or an integration problem. It is three structural gaps in the enterprise environment that a pilot does not surface and a production deployment cannot survive without.

Gap One: The Agent Finds Everything, Including What It Shouldn't Trust
A pilot environment is curated. Before the demo, the team selects a set of certified reports, defines which KPIs are in scope, and builds the pilot on that controlled subset. The agent performs well because it has been given trustworthy inputs.
Production is different. In production, the agent queries the full analytics estate, and most enterprise analytics estates are not curated. Organizations implementing ZenOptics typically find that 30 to 40 percent of their analytics estate consists of duplicate or conflicting reports. That means for every clean, certified version of a metric or dashboard, there are likely one or more shadow versions in the environment: built by different teams, using different calculation logic, for purposes that may have been relevant three years ago and are not today.
The agent has no visibility into any of this. It cannot see certification status. It cannot see that a report has no active owner. It cannot distinguish the revenue figure the CFO uses for quarterly reporting from the revenue figure a regional team built for a campaign analysis that never reconciled with finance. It queries what it finds. All of it looks equivalent to the agent.
The failure mode is predictable: the agent surfaces an answer that does not match the figure the stakeholder already knows to be correct. The stakeholder does not conclude that the agent found an uncertified report. The stakeholder concludes that AI cannot be trusted. That perception is sticky. Recovering stakeholder confidence after it is lost is significantly harder than establishing it in the first place.
The Hidden Cost of Analytics Sprawl examines how estate debt accumulates and why it becomes the primary blocker to AI adoption, not because AI doesn't work, but because the estate it runs on was never designed with AI access in mind.
Gap Two: Statistical Probability Is Not Business Context
The second gap is the one that vendor presentations routinely treat as already solved: the AI understands what the data means.
It does not. Not in the way enterprise analytics requires.
Without a machine-readable analytics context layer to ground it in business meaning, what an AI agent understands is statistical relationships. It can infer that "revenue" and "net revenue" are related. It can observe that they appear near the same dashboards and are referenced together in similar queries. It can produce a coherent response that treats them as related concepts. What it cannot do is apply the business definition the CFO has approved for quarterly reporting. It cannot apply the rule that net revenue for the commercial team excludes contra-revenue items that the finance team includes. It cannot know that a particular metric rolls up to a specific KPI that feeds a specific forecast model, or that the definition of that KPI was revised eighteen months ago and only applies to transactions after a certain date.
That information exists in the organization. It lives in governance documents that were written for humans, in the institutional knowledge of senior analysts who have been there long enough to remember the revision history, and in spreadsheets that function as unofficial business glossaries because no one ever built the formal version. None of it is machine-readable. The agent fills the gaps with statistical inference. The output is coherent. It sounds right. It is wrong in ways that only someone with deep organizational context would catch, and it is wrong inconsistently, which makes the pattern hard to diagnose.
The downstream effect is not a single incorrect answer that gets corrected. It is a pattern of answers that are sometimes right, sometimes wrong in ways that are hard to predict, and that erode trust systematically over time. Stakeholders learn that they cannot rely on AI-generated analytics without manually verifying against their own knowledge. At that point, the agent has added work, not removed it.
Automated context generation (deriving the business definitions, KPI relationships, and semantic structure that already exist within the organization's BI metadata and making that machine-readable) removes this gap. Organizations implementing ZenOptics typically see AI deployment timelines compress two to three times once that context layer is in place, because the months of manual semantic build work that previously preceded any AI deployment are replaced by automated derivation from existing BI metadata.
Gap Three: What Ungoverned Agent Actions Cost in Regulated Environments
The third gap surfaces last. In a demo, it is invisible. In a regulated enterprise, it is the one that makes the deployment unviable.
A demo proves that an agent can answer questions. A production deployment in a regulated industry requires the agent to do something additional: everything it produces and every action it triggers must be auditable. What data informed this response? Which certified metric did this recommendation draw on? What business process rules governed the agent's action? What was the outcome, and who is accountable for it?
Gartner projects that by 2030, 50 percent of AI agent deployment failures will be due to insufficient governance platform runtime enforcement. The organizations behind those failures are not running ungoverned agents by accident. They are running agents that were designed for demo environments, where governance is not a requirement, and discovered in production that governance cannot be retrofitted.
The problem with retrofitting is not technical complexity alone. It is the nature of decision lineage. If the trace from input to recommendation to action was not captured from the start, it cannot be reconstructed. When an AI-influenced decision needs to be explained to a regulator, an auditor, or a board risk committee, the absence of that trace is not a documentation gap. It is evidence that the decision process was not auditable. In financial services, insurance, healthcare, and other regulated contexts, that is not a recoverable position.
Governing agent actions from the beginning (mapping every AI-driven step to approved business processes, capturing decision lineage continuously, and monitoring agent behavior within defined boundaries) is not optional overhead. It is the infrastructure that makes the deployment possible in the first place. For a deeper treatment of what enterprise-scale AI governance requires in the analytics context, Governing Autonomous Analytics AI at Enterprise Scale covers the architecture and the regulatory pressures driving it.
The Three Gaps Almost Always Appear Together
The pattern across stalled agentic analytics deployments is consistent: the three gaps are not independent. An ungoverned estate almost always means an absent context layer, because organizations that have not certified their analytics assets have typically not structured the business definitions those assets carry either. A missing context layer almost always means ungoverned execution follows, because agents operating without business context take action on outputs that have not been validated against the business rules that should govern them.
Organizations that address only one gap get further in the pilot. They do not make it to production. The organizations that have completed the transition consistently report the same finding: what changed was not the AI model and not the BI tooling. What changed was the three layers of infrastructure underneath: a certified analytics estate the agent can trust, an analytics context layer that makes its outputs accurate, and a governed execution environment that makes those outputs deployable in the organization's real operating context.
What that infrastructure looks like, and how Atlas, Nexus, and Maestro close each gap, is mapped out in Agentic Analytics in the Enterprise: From Pilot to Production.
Frequently Asked Questions
What percentage of agentic AI projects make it to production? Industry-wide data on pilot-to-production conversion rates is still emerging, but Gartner's projection is direct: more than 40% of agentic AI projects will be canceled by end of 2027, citing escalating costs, security concerns, and failure to demonstrate business value. The implication is that the majority of organizations currently running pilots will not complete the transition to production without addressing the structural gaps that pilots conceal.
What is the most common reason agentic analytics fails in enterprise deployments? The most common failure is not a technology failure. It is an infrastructure failure. Specifically: the analytics estate the agent queries is ungoverned, so the agent surfaces inconsistent or uncertified outputs. The AI operates without a machine-readable context layer, so its responses are statistically reasonable but contextually wrong in ways that erode stakeholder trust. And the deployment lacks a governed execution layer, so agent actions cannot be audited or attributed. Any one of these gaps is sufficient to stall a deployment; they tend to appear together.
How do you assess whether your analytics estate is ready for agentic AI? Three indicators determine readiness. First, certification coverage: what percentage of analytics assets in your environment are certified as authoritative, with a designated owner and a known last-review date? If the answer is below 60 to 70 percent, the estate is not agent-ready. Second, context availability: does your organization have machine-readable business definitions for the KPIs and metrics AI agents will query? If that context lives only in documents and institutional knowledge, the context layer is absent. Third, governance architecture: does your execution environment capture decision lineage from AI-driven actions, map those actions to approved business processes, and monitor agent behavior against defined boundaries? If not, the governed execution layer is missing.
Why does governance matter more for agentic analytics than for traditional BI? In traditional BI, a human reviews every output before acting on it. The human provides an implicit governance layer: catching errors, checking context, and taking accountability for the decision. In agentic analytics, the agent acts continuously, often across multiple steps, without a human reviewing each output. The governance that was implicit in human review has to become explicit in the platform. Without it, the agent operates as a black box, producing outputs that cannot be attributed, audited, or traced back to the certified metrics and approved processes that should govern them.
Can a failing agentic analytics deployment be fixed by switching AI models? Almost never. If the pilot produced inconsistent outputs or failed to gain stakeholder trust, the cause is almost always in the estate and context layers, not in the model. A better model querying an ungoverned estate returns better-articulated wrong answers. Switching models without addressing the underlying infrastructure gaps is the analytics equivalent of upgrading the engine in a car with no roads. The investment in the model is wasted until the foundation is in place.
How does a missing analytics context layer differ from a data quality problem? Data quality problems affect the accuracy of the underlying data records. A missing analytics context layer affects the AI's ability to interpret what those records mean. An organization can have high-quality, accurate data and still produce wrong AI outputs if the agent does not understand what "revenue" means in the context of this business, how it differs from "net revenue," or which version of the metric is authoritative for a given reporting context. The two problems have different symptoms and different fixes: data quality requires data engineering; context requires structured business definitions, KPI relationships, and semantic metadata that AI agents can consume.
Published May 29, 2026Why Agentic Analytics Pilots Fail in Production
Most agentic analytics pilots look great in demos but stall in production. Learn the three structural gaps that kill projects and how to build an AI-ready estate.
Schedule a 15min demo call