





Most enterprise analytics teams now understand that AI needs certified metric definitions to produce trusted outputs. That understanding has driven investment in analytics governance, metric certification programs, and context layer infrastructure. What is less understood is that a flat list of certified definitions, even a well-governed one, is not sufficient for AI to reason correctly across a complex BI estate.
When an AI agent synthesizes an answer that spans revenue, margin, churn, and volume metrics, it needs to understand how those metrics relate to each other, not just what each one means in isolation. The difference between AI that retrieves individual certified facts and AI that reasons accurately across a full analytics estate is the graph structure that encodes those relationships. That structure is the analytics knowledge graph, and it is the component of the analytics context layer that most enterprise AI deployments are missing.
Why Certified Metrics Alone Are Not Enough for Enterprise AI
Single-metric queries are the exception in enterprise analytics. "Why did operating margin compress in Q2?" requires an AI agent to traverse revenue recognition adjustments, cost of goods sold, pricing changes, and volume variances, understanding how each metric relates to the next, which version of each is certified, and in what sequence they form the answer the business is actually asking for.
Without a graph structure that encodes those relationships, the AI constructs the connections itself through statistical inference. It observes that certain metrics frequently appear together in reports and dashboards, infers a relationship, and builds its reasoning chain from that inference. The answer it produces is statistically grounded. It is not grounded in the organization's approved business logic, and there is no governance layer in that reasoning chain that an auditor, a CDO, or a compliance function can inspect or validate.
The practical consequence is familiar to any enterprise that has deployed an AI copilot against a multi-tool BI estate: the agent produces answers that are directionally plausible, occasionally correct, and inconsistent enough across sessions that business users do not act on them without manual verification. The tool is working correctly. The relational structure it needs to reason correctly is absent.
What an Analytics Knowledge Graph Is
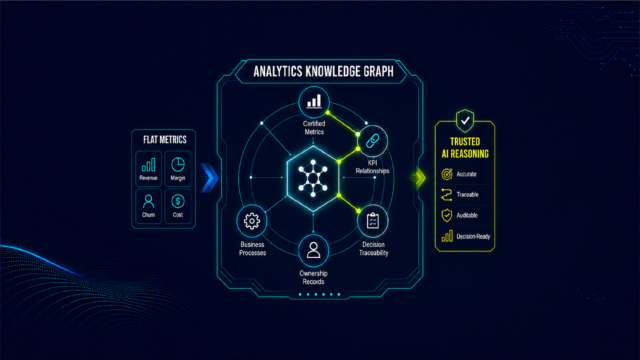
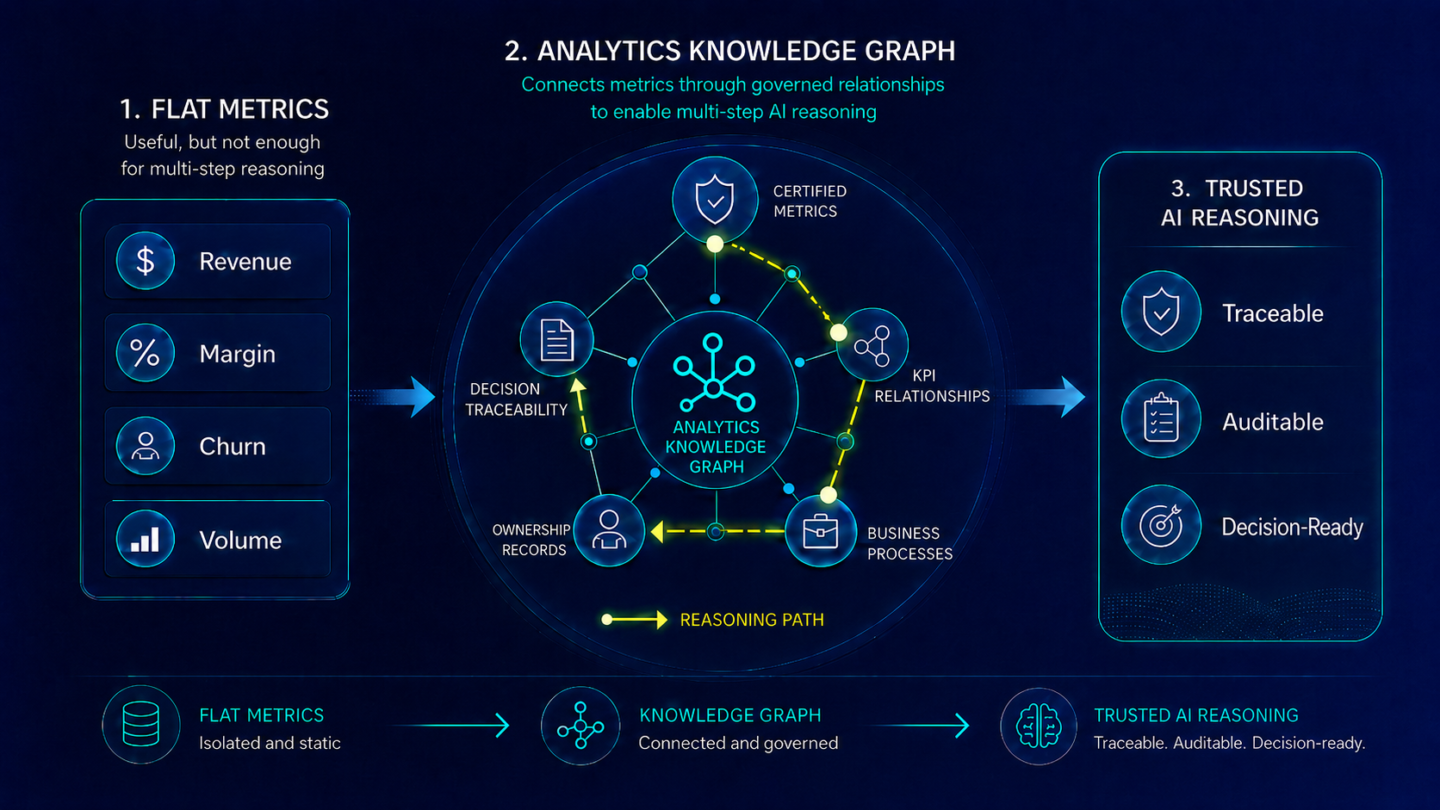
An analytics knowledge graph is a graph structure in which every node is a certified analytics asset and every edge encodes a governed relationship between those assets. Nodes include metrics, KPIs, reports, dashboards, business processes, and the ownership records that certify each one. Edges encode the relationships that matter for AI reasoning: which metrics roll up into which KPIs, which reports draw on which certified metrics, which KPIs govern which business decisions, and who is accountable for each definition in the chain.
This is not a general-purpose knowledge graph of the kind used in search engine infrastructure or enterprise ontologies. Those graphs encode relationships between entities in the world. An analytics knowledge graph encodes relationships between certified analytics assets in this organization, governed by the policies and ownership structures this organization has established. The relationships are not derived from semantic similarity. They are derived from the actual governance structure of the analytics estate: which metrics are certified together, which ownership chains govern related KPIs, and which business processes connect specific metric definitions to specific decision workflows.
The distinction matters because two metrics that are semantically close, "gross revenue" and "net revenue" for example, may carry entirely different governance rules, entirely different ownership chains, and entirely different constraints on which AI systems are permitted to act on them and for what purpose. A graph built on semantic similarity treats them as nearly identical. An analytics knowledge graph treats them as distinct governed entities with a defined relationship that AI must navigate correctly rather than approximate statistically.
Why a Flat Context Layer Is Not Enough for Multi-Step Reasoning
The analytics context layer captures four categories of information that AI systems need: metric definitions, relationships, ownership and certification, and process context. A flat implementation of that layer, a structured catalog of certified metric definitions with ownership records, answers the question "what does this metric mean?" correctly and completely.
It does not answer the question that multi-step agentic workflows require: how does this metric relate to every other metric that matters for this decision, and in what sequence should those metrics be traversed to produce a grounded answer?
A senior finance analyst reasoning through an operating performance question does not look up one metric at a time. The analyst holds a mental model of how the relevant metrics connect, which ones are authoritative for which purposes, and which sequence of analysis the organization has established as the approved approach for that class of question. That mental model is organizational knowledge accumulated over years. An AI agent operating without a graph structure has no access to it. It reconstructs an approximation of it from statistical patterns in the data it can see.
The analytics knowledge graph makes that organizational knowledge explicit, machine-readable, and available to every AI system that needs it. The certified sequence of metrics for an operating performance analysis is encoded in the graph. The agent follows the graph rather than reconstructing it from inference, and the answer it produces reflects the organization's actual business logic rather than a statistical approximation of it.
How the Analytics Knowledge Graph Differs from Adjacent Infrastructure
The analytics knowledge graph is frequently conflated with two existing infrastructure categories. Understanding what each one does and does not do clarifies why the graph is a distinct requirement.
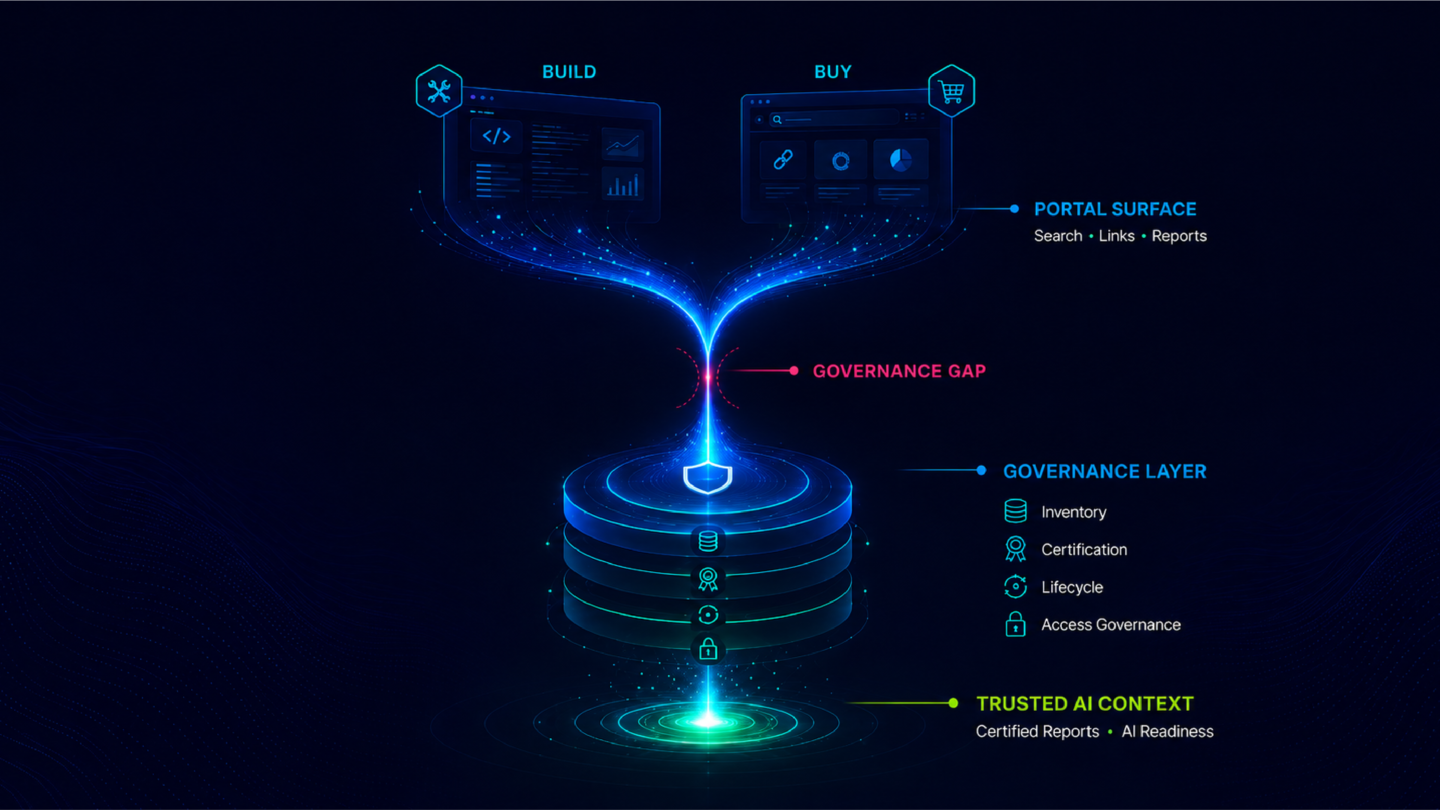
A semantic layer maps technical data field names to business-readable metric names and pre-computes standard calculations. It handles the translation between the data warehouse and the BI tool. It does not encode the governance relationships between metrics, the ownership chains that certify them, or the process context that determines how AI systems should traverse them. The distinction between the analytics context layer and the semantic layer covers this in full. The knowledge graph is the relational structure built on top of the context layer: it requires the semantic layer as a foundation and extends well beyond it.
A data catalog documents raw data assets: tables, schemas, fields, data quality records, and technical lineage from source to destination. It operates at the infrastructure layer. An analytics knowledge graph operates at the analytics layer, encoding relationships between the certified business metrics and KPIs that sit on top of the data infrastructure. The catalog tells data engineers what data exists. The knowledge graph tells AI agents how certified analytics relate to each other within the organization's governance structure.
How Enterprise Analytics Knowledge Graphs Enable Trusted AI Reasoning
Nexus, ZenOptics's AI Context Layer for Analytics, is organized around three capabilities: Metadata Onboarding, the Semantic Curation Studio, and the Knowledge Graph. The Knowledge Graph is the relational layer built on top of the certified analytics estate that Atlas governs.
It is not manually constructed. Enterprise analytics estates contain decades of accumulated business knowledge embedded in their existing BI metadata: report hierarchies, dashboard structures, metric dependencies, KPI roll-up logic, usage patterns, and ownership records. The Modern analytics knowledge graph platforms can derive relationships from existing BI metadata, reducing the need for extensive manual modeling.
The graph is maintained continuously. As the analytics estate evolves, as new metrics are certified, existing ones retired, and BI tools added or replaced, the graph updates to reflect the current state of the certified estate rather than its historical approximation. This is the same principle that governs the context layer overall: a static, manually constructed artifact decays as the business changes. A continuously maintained graph derived from live BI metadata stays current.
Three AI capabilities become available when AI agents operate against the Nexus Knowledge Graph rather than a flat context layer.
The first is multi-hop metric reasoning. An agent answering a multi-metric business question traverses the graph along governed edges rather than constructing the reasoning chain through statistical inference. Each step in the reasoning follows a relationship that the organization has certified, not a relationship the agent inferred from co-occurrence patterns.
The second is conflict detection. When two metrics in the same reasoning chain carry conflicting definitions, the graph surfaces the conflict before the agent incorporates both into its answer. Without the graph, the agent has no mechanism to detect that a conflict exists. It synthesizes a response from both definitions and produces an answer that is internally inconsistent in ways that are hard to diagnose after the fact.
The third is decision traceability. When an AI agent's recommendation can be traced node by node through the knowledge graph, from the decision back through the KPIs that informed it, through the certified metrics those KPIs are built on, to the ownership and certification records that validate each one, the trace is complete, auditable, and available to compliance and risk functions without manual reconstruction. The governance that analytics context engineering establishes is what makes the graph traceable. The graph is what makes the trace machine-readable at scale.
The Connection Between the Knowledge Graph and Governed AI Execution
Decision traceability for enterprise AI requires more than the ability to log what an agent did. It requires the ability to trace why the agent produced the output it did, grounded in the specific certified analytics that informed each step of its reasoning.
A knowledge graph is the infrastructure that makes that traceability structural rather than reconstructed. When the reasoning chain is encoded in a governed graph, the trace exists as a property of the graph itself. Every node the agent traversed, every edge it followed, every certified metric it applied is recorded in the graph structure. The compliance function does not reconstruct the trace from logs. It reads the trace from the graph.
This is also what separates governed AI execution from capable AI execution. Agentic analytics deployments that reach production share a common characteristic: the reasoning the agent performs is grounded in a certified, traceable structure that the organization controls. The analytics knowledge graph is that structure. It is what allows enterprises to extend AI agents into consequential decision workflows, not because the agent is more capable, but because the reasoning it performs can be verified, audited, and governed.
Frequently Asked Questions
What is an analytics knowledge graph?
An analytics knowledge graph is a graph structure in which nodes represent certified analytics assets (metrics, KPIs, reports, business processes, ownership records) and edges represent governed relationships between those assets. It encodes the relational structure of the analytics estate so that AI agents can reason across multiple metrics in sequence, following certified governance logic rather than constructing relationships through statistical inference. It is the component of the analytics context layer that makes cross-metric AI reasoning accurate and auditable.
How is an analytics knowledge graph different from a semantic layer?
A semantic layer translates technical data field names into business-readable metric names and pre-computes standard calculations. It handles query-time translation between the data warehouse and BI tools. An analytics knowledge graph encodes the governance relationships between certified metrics: which KPIs connect to which business decisions, which metrics carry the same name but different definitions across business units, which ownership chains certify each metric, and in what sequence metrics should be traversed for a given class of question. The semantic layer is a prerequisite; the knowledge graph extends beyond it into the relational governance structure of the certified analytics estate.
Why do AI agents need a graph structure rather than a flat list of metric definitions?
A flat list of certified definitions enables AI to answer single-metric questions accurately. Multi-step analytical questions require the agent to traverse relationships between metrics in sequence, applying the correct certified definition at each step and maintaining consistency of business logic across the full reasoning chain. Without a graph that encodes those relationships, the agent constructs them through statistical inference, producing answers that are plausible but not grounded in the organization's approved analytical logic. The graph is what makes multi-metric AI reasoning governable rather than approximate.
Is the analytics knowledge graph built manually?
Not with ZenOptics. The Nexus Knowledge Graph is derived automatically from the BI metadata that already exists within the organization's analytics estate: report hierarchies, dashboard structures, metric dependencies, usage patterns, and ownership records. The graph reflects the actual governance relationships encoded in the estate rather than a theorized specification constructed from scratch. It is also maintained continuously as the estate evolves, so the graph stays current without requiring periodic rebuild cycles.
What does decision traceability look like in a knowledge graph structure?
When an AI agent reasons through a business question using the knowledge graph, every step of its reasoning follows a governed edge between certified nodes. The trace from the agent's recommendation back to the certified metrics that informed it is encoded in the graph structure itself. Compliance and risk functions read the trace from the graph rather than reconstructing it from logs. This is what makes AI-influenced decisions auditable at scale: the governance structure of the reasoning is a property of the graph, not a post-hoc reconstruction from the agent's output.
How does the Nexus Knowledge Graph connect to Atlas?
Atlas is ZenOptics's Analytics System of Record: it inventories the analytics estate across BI tools, certifies authoritative metrics and reports, assigns ownership, and maintains the governance records for the full estate. The Nexus Knowledge Graph is built on top of that certified estate. Atlas produces the certified nodes (each metric, KPI, report, and ownership record) that the graph connects. Nexus derives the relational structure from the metadata Atlas governs and makes the graph machine-readable for AI agents and agentic workflows. The two systems together produce a certified, relational, continuously maintained analytics context layer.
How does the knowledge graph change the time required to deploy new AI use cases?
Without a knowledge graph, each new AI use case requires manual specification of the metric relationships the agent needs to navigate: which KPIs connect to which decisions, which metrics are authoritative for which reporting context, and what sequence the agent should follow. That specification work happens once per use case and must be repeated when the business or the BI estate changes. With the Nexus Knowledge Graph in place, the relational structure is already derived and maintained. New AI use cases deploy against the existing graph rather than requiring new specification work, which compresses deployment timelines two to three times, consistent with what organizations implementing ZenOptics typically see once the context layer is in place.
Published June 19, 2026How Enterprise AI Actually Reasons Across Metrics
When AI answers questions about revenue, margin, churn, and risk, it needs more than certified metric definitions. It needs an analytics knowledge graph that encodes how every trusted metric, KPI, and report connects so agents can reason step by step instead of guessing from patterns. See how ZenOptics Nexus builds this governed graph on top of Atlas to make cross-metric AI reasoning auditable, conflict-aware, and safe to deploy in real decision workflows.
Schedule a 15min demo call