





The word "hallucination" has become the default explanation for enterprise AI outputs that cannot be reconciled with what the business knows to be true. A revenue figure the CFO does not recognize. A churn rate that contradicts the CRM. A margin number three finance teams disagree on, each of whom is certain their version is correct. When the AI returns one of these irreconcilable answers, the diagnosis is almost always the same: the model hallucinated.
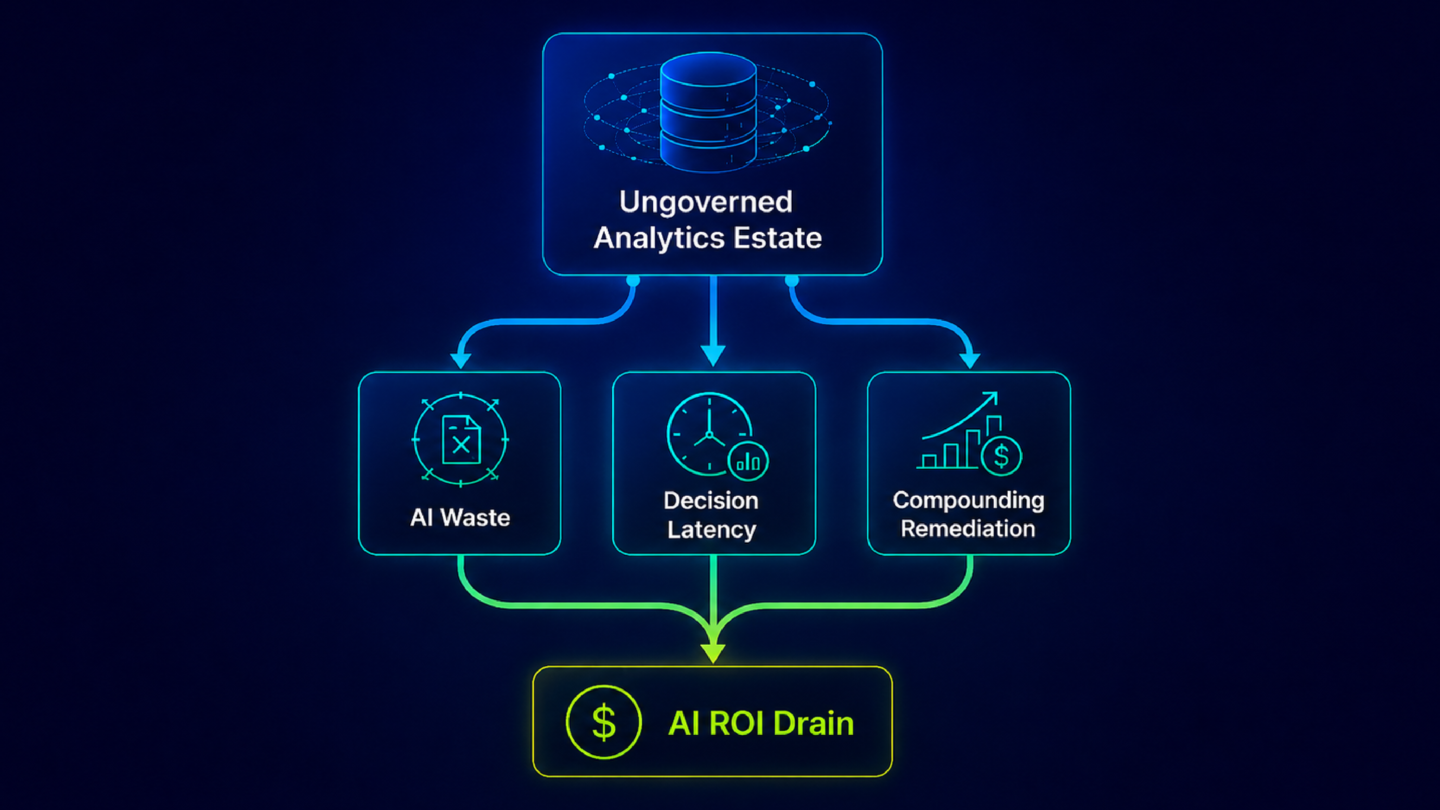
In the majority of enterprise analytics failures, that diagnosis is wrong. And acting on it leads organizations to invest in the wrong fix while the actual problem compounds. The model did not hallucinate. It read an ungoverned analytics estate and returned exactly what it found. The distinction between those two things is not semantic. It determines whether the next investment goes toward model improvement or toward the governance program that actually resolves it.
What "Hallucination" Actually Means, and Where It Applies
Hallucination, in the precise sense, refers to a model generating plausible-sounding content with no grounding in the source data it was given. The model produces a citation that does not exist, a statistic with no source, a fact that has no basis in any document it read. This is a documented model behavior in generative language tasks, and it is a legitimate concern for enterprise teams deploying AI in content generation, summarization, and research contexts.
It does not describe what happens when an enterprise AI copilot returns a revenue figure the CFO cannot reconcile.
In analytics contexts, AI agents and copilots are not generating content from nothing. They are reading from the organization's BI estate: its reports, dashboards, certified metrics, and KPI definitions. They return what they find there. The failure mode in enterprise analytics is not fabrication. It is misinterpretation of a poorly governed source environment. The AI is doing exactly what it was designed to do. The environment it is reading from is the problem.
Applying the hallucination label to this failure pattern is not just imprecise. It directs organizations toward model-level interventions that cannot fix a governance-level condition. Teams that have spent quarters on prompt engineering, retrieval-augmented generation tuning, and model fine-tuning to address "AI hallucination" in their analytics outputs, and still cannot get consistent trusted answers, are experiencing the consequence of that misdiagnosis.
What Enterprise Analytics AI Actually Does When It Gets It Wrong
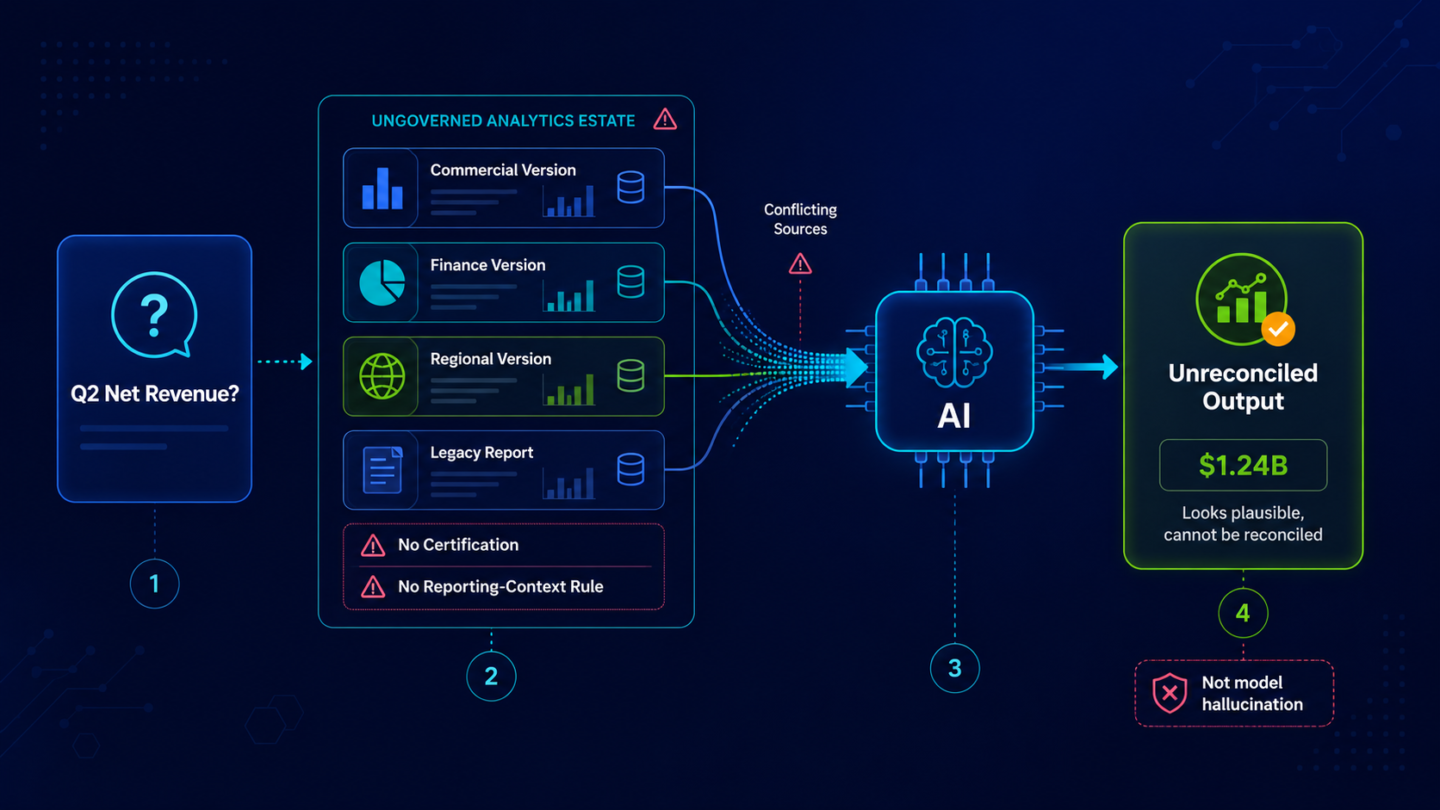
To understand the actual failure mechanism, it helps to follow a single query through an ungoverned analytics estate.
A business leader asks an AI copilot: what was our net revenue for Q2? The copilot queries the organization's BI environment. What it finds is not one answer. It finds three versions of a metric that all carry the name "net revenue" or a close variant. The commercial team's version excludes deferred revenue adjustments that finance applies at close. The consolidated finance version includes those adjustments but uses a different currency conversion rate than the version the regional leads rely on. A legacy SSRS report that has been in the estate since 2021 carries a third calculation that matched the old revenue recognition policy before it was updated.
The copilot has no mechanism to identify which version is certified as authoritative, because no certification exists. It has no governance rule telling it which version applies to which reporting context. It reads all three, applies whatever statistical weighting its architecture uses to reconcile conflicting sources, and returns a number. That number is not fabricated. It corresponds, in some weighted average sense, to the content of the estate it read. It also does not match any of the three versions cleanly, which is why no one in the room can reconcile it.
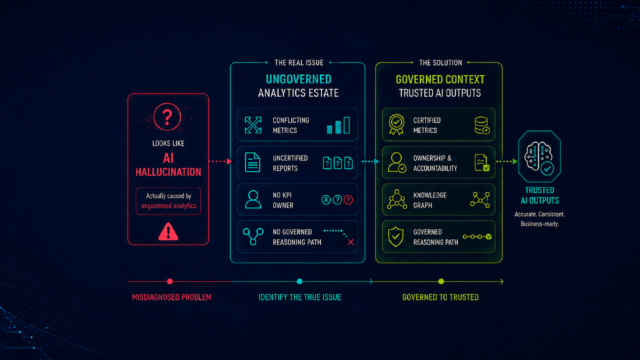
That is not hallucination. That is an accurate output from an AI operating against an ungoverned analytics estate. The governance failure is what produced the wrong answer. The model is a bystander.
Why the Model Cannot Fix a Governance Problem
The interventions that follow an "AI hallucination" diagnosis are predictable. Better model versions. Tighter system prompts instructing the AI to use specific metric definitions. Retrieval-augmented generation designed to pull from curated source documents. Fine-tuning on domain-specific data to improve accuracy.
Each of these addresses model behavior. None of them addresses the condition that produced the problem: multiple conflicting versions of the same metric in the analytics estate, with no certification designating one as authoritative, and no relational structure governing how AI should traverse them in multi-metric reasoning.
A better model reading the same ungoverned estate does not produce a correct answer. It produces a more confident wrong answer, because the model's increased capability allows it to synthesize the conflicting sources more fluently into a response that sounds authoritative. A tighter prompt encoding one definition of net revenue cannot account for the dozens of net revenue variants that exist in the estate and that the agent may encounter in subsequent queries or multi-step analytical tasks. Each new prompt is a patch against a specific failure. The estate continues to accumulate ungoverned variants. The patches cannot keep pace.
The fix for a governance failure is governance. Everything else is a workaround that degrades as the estate grows.
The Three Governance Failures That Produce Outputs Teams Cannot Trust
Three specific conditions in an enterprise analytics estate generate the AI trust failures that get misdiagnosed as hallucination. Each is recognizable to anyone who has managed a large BI environment.
Conflicting KPI definitions across business units. This is the most common condition and the most invisible one, because every team believes its definition is correct. Commercial uses gross revenue excluding adjustments because that is how it tracks sales performance. Finance uses net revenue including adjustments because that is what the audited P&L requires. Operations uses a volume-weighted variant that aligns with how supply chain is planned. All three definitions are named "revenue" or a variant of it in their respective dashboards. An AI agent querying across all three has no basis for choosing between them without a certification layer designating which version is authoritative for which reporting context. It synthesizes across all of them and returns an answer that matches none.
Uncertified analytics assets in the reasoning path. Enterprise BI estates accumulate reports and dashboards faster than they retire them. ZenOptics data shows that 30 to 40 percent of the typical enterprise analytics estate consists of duplicate or conflicting assets, many of which have no active owner, no certification status, and no review cycle. An AI agent cannot distinguish a certified authoritative dashboard from a shadow report a regional analyst built eighteen months ago and never updated. Both appear in the estate. Both are read with equal weight. The uncertified asset contaminates the reasoning path.
No relational structure for multi-metric reasoning. When an AI agent answers a question that spans multiple metrics, it must construct the relationships between those metrics to form a coherent answer. Without a governed relational structure, the agent builds those relationships through statistical inference, observing which metrics frequently appear together in the estate and inferring a relationship from that pattern. The analytics knowledge graph is what provides the governed path instead: a structure in which every relationship between certified metrics is encoded, maintained, and available for AI agents to follow. Without it, multi-metric answers are inference chains presented as analytical conclusions.
What Changes When the Analytics Estate Is Governed
The same query against a governed analytics estate produces a different result. Not because the model is different. Because what the model reads is different.
The business leader asks the same question: what was our net revenue for Q2? The AI copilot queries the estate. Atlas, ZenOptics's Analytics System of Record, has certified one version of net revenue as authoritative for commercial reporting, with the finance team's consolidated version designated for P&L purposes. The certification record includes the metric owner, the last review date, and the specific reporting contexts each version governs. The Nexus Knowledge Graph encodes the relationship between the two versions and which context governs each.
The copilot reads the estate, follows the graph, identifies the query as a commercial reporting context, and applies the certified commercial version of net revenue. The answer it returns matches what the commercial team expects, because it came from the certified source that governs that reporting context. When the CFO asks the same question for P&L purposes, the agent applies the finance version. The answers differ, as they should, and both are traceable to certified sources.
The model is the same. The governance is different. That is the entire resolution.
This is why the analytics context layer is the infrastructure that makes AI analytics outputs trusted: it is the layer that provides the certified definitions, the ownership records, and the relational structure that AI needs to read the estate correctly rather than approximate it statistically.
How to Diagnose Whether You Have a Model Problem or a Governance Problem
Before investing in model-level remediation, three diagnostic questions identify whether the failure is a model problem or a governance problem.
Can you trace the AI's answer to a specific analytics asset in the estate? If the answer can be traced to a specific report, dashboard, or metric definition in the BI environment, and that asset is either uncertified, outdated, or one of several conflicting versions, the failure is a governance problem. The model read what was there. If the answer has no traceable source in any analytics asset the organization has, that is a stronger signal of model-level behavior worth investigating separately.
Does the same query return inconsistent answers across sessions? Session-to-session inconsistency with the same underlying data is a governance signature. The agent is reaching different assets in an uncertified estate on each query, and weighting them differently based on which combination it encounters. Genuine model hallucination tends toward a different inconsistency pattern: generating novel content that varies in substance rather than bouncing between existing conflicting sources in a way that reflects the estate's actual variant distribution.
Do multiple teams each recognize the answer as close to their version but not exactly right? This is the clearest governance signature of all. Each team's variant of the metric is present in the estate. The AI synthesized across them because no certification designated one as authoritative. Each team sees a reflection of their own definition in the output but cannot reconcile it with anyone else's. No model improvement resolves this. Designating one version as authoritative and governing the estate around that designation does.
For the organizational practice that governs the estate once the diagnosis is confirmed, analytics context engineering covers what the function looks like and where it sits in the enterprise.
Why This Distinction Matters for How CDOs Present AI Programs to Leadership
The diagnosis an AI program carries shapes the conclusions leadership draws from its failures. When AI analytics outputs are attributed to model hallucination, two responses are common. The first is that the AI tools need to be replaced with more accurate alternatives. The second is that AI is not mature enough for enterprise analytics deployment, and the program should be paused until model reliability improves. Both conclusions follow logically from the hallucination diagnosis. Both are wrong when the actual failure is governance.
When the failure is correctly identified as an analytics governance problem, the path is defined, actionable, and owned by the CDO rather than dependent on model vendors. The analytics estate needs to be inventoried. Authoritative metrics need to be certified. A context and relational layer needs to be built on top of the certified estate. These are programs a data and analytics organization can execute, with clear milestones and measurable outcomes at each stage as governance coverage expands across the estate.
The reframe also changes the ROI conversation. A CDO presenting an analytics governance program as the path to trusted AI outputs is presenting a business case that leadership can fund and evaluate. A CDO asking for budget to try better models against the same ungoverned estate is presenting a bet with no clear mechanism for improvement. The distinction between data governance and analytics governance matters here: analytics governance is the specific program that addresses the layer where AI operates, and it is the program leadership needs to understand and invest in.
The organizations that produce trusted AI analytics outputs are not the ones with the most capable models. They are the ones that governed their analytics estates before demanding that AI reason across them.
Frequently Asked Questions
What is the difference between AI hallucination and an analytics governance failure?
AI hallucination refers to a model generating plausible-sounding content with no grounding in the source data it was given. It is a documented behavior in generative language tasks. An analytics governance failure occurs when AI reads from an ungoverned analytics estate, one with conflicting metric definitions, uncertified assets, and no relational structure to govern multi-metric reasoning, and returns an output that reflects the estate's contradictions rather than the organization's correct business logic. The model behavior is sound in the second case. The source environment is not. The two failure modes require different fixes: model-level intervention for genuine hallucination, governance investment for analytics estate failures.
Why do enterprise AI tools return different answers to the same question across sessions?
Session-to-session inconsistency is typically a governance signature rather than a model failure. In an ungoverned analytics estate, multiple versions of the same metric coexist without certification designating which is authoritative. An AI agent querying the estate encounters different combinations of these variants on each session, depending on retrieval patterns, recency weighting, and which assets the query surface returns. The agent synthesizes a response from whichever combination it encounters. Each response reflects the estate's content accurately. None reflects the organization's correct business logic because no certification has established what that logic is.
Can prompt engineering fix analytics AI trust failures?
Prompt engineering addresses individual interactions by encoding specific business context into the instructions sent to the AI system. It works for controlled use cases where the metric definitions are known and the query scope is bounded. It does not scale to enterprise analytics environments where hundreds of metrics, dozens of business units, and multiple AI tools all need consistent, governed definitions. Each prompt encodes a definition for one query. The ungoverned estate continues to accumulate conflicting variants. New queries encounter those variants without the benefit of the prompt that was written for a different session. Analytics governance builds the infrastructure that eliminates the need for that patch.
What does a certified analytics estate look like, and how does it prevent AI trust failures?
A certified analytics estate is one in which every authoritative metric and report has been designated as such, with an accountable owner, a last-reviewed date, and a clear record of which reporting contexts that version governs. AI agents querying a certified estate do not encounter ambiguity about which version of a metric to use: the certification record provides the answer. Combined with the relational structure of the analytics knowledge graph, which encodes how certified metrics relate to each other and in what sequence they should be traversed for different classes of questions, a certified estate gives AI the governed foundation it needs to produce consistent, traceable outputs.
How do I know if my AI analytics problem is a model problem or a governance problem?
Three diagnostics: first, trace the AI's answer to a specific asset in the BI estate. If it traces to an uncertified or conflicting source, that is governance. Second, check whether the same query returns inconsistent answers across sessions with the same underlying data. Session inconsistency that reflects the estate's variant distribution is a governance signature. Third, ask multiple teams whether they recognize the AI's output as close to but not exactly matching their version of the relevant metric. If every team recognizes a partial reflection of their variant, the AI synthesized across ungoverned definitions. None of these point to model improvement as the correct path.
Does this apply to Microsoft Copilot specifically?
Yes. Microsoft Copilot, like any AI agent or copilot, reads from the analytics environment it is connected to. When that environment contains conflicting Power BI metric definitions, uncertified reports, and no governance layer designating which KPIs are authoritative for which reporting contexts, Copilot returns answers that reflect those conflicts. Microsoft's own documentation on Copilot readiness acknowledges that ambiguous measure names in Power BI semantic models produce ambiguous Copilot responses. The ambiguity is in the estate, not in Copilot. Governing the analytics layer that Copilot reads from, through certification, ownership, and a context layer that Copilot can trust, is what produces reliable Copilot outputs. The tool does not need to be replaced. The estate it reads needs to be governed.
Published June 22, 2026Enterprise AI Doesn't Hallucinate. It Reads Ungoverned Analytics.
If your AI analytics outputs are inconsistent and the instinct is to blame the model, the actual cause is almost certainly the analytics estate beneath it. Schedule a 15-minute working session with ZenOptics to review your estate and what governance coverage would change.
Schedule a 15min demo call