





Retrieval-Augmented Generation has become the standard architecture for enterprise AI deployments that need to operate on organizational knowledge rather than general training data. In analytics contexts, the argument for RAG is straightforward: point the retrieval system at the BI estate, and the AI will pull the relevant reports, metric definitions, and KPI data it needs to answer business questions accurately. The model stops relying on what it was trained on and starts working with what the organization actually has.
That argument is correct as far as it goes. RAG addresses a real problem. It gives AI systems access to current, organization-specific content at query time rather than approximating it from training weights. In enterprise analytics, that access matters.
What RAG does not address is the governance problem: whether what it retrieves is the certified, authoritative version of each metric, whether the sources it surfaces have been designated as trustworthy for AI use, and whether the relational structure that connects those metrics is encoded in a way AI can follow. Access and governance are different problems. RAG solves the first one. The second requires a different layer entirely.
What RAG Was Built to Do
Retrieval-Augmented Generation emerged as a solution to a specific limitation of large language models: the knowledge cutoff. Models trained on data up to a fixed point cannot answer questions about events, documents, or organizational information that postdates their training. RAG addresses this by retrieving relevant content from a connected knowledge source at query time and providing it to the model as context, giving the AI access to current, specific information rather than forcing it to approximate from stale training weights.
In enterprise analytics deployments, RAG is used to connect AI tools to the organization's BI content: reports, dashboards, KPI definitions, and metric documentation stored in knowledge bases, analytics catalogs, or document repositories. When a business leader asks the AI about Q2 margin performance, the RAG system retrieves the relevant content from the connected knowledge base and passes it to the model as context. The model generates an answer from what was retrieved rather than from general knowledge.
This is genuinely useful infrastructure. It is also the right solution to the access problem: making the organization's analytics content available to AI at query time. The limitation is not in what RAG was designed to do. It is in what RAG was never designed to do: evaluate the trustworthiness of what it retrieves, enforce certification hierarchies, or encode the governance relationships between metrics that AI needs to reason correctly across a complex analytics estate.
What RAG Cannot Do
RAG retrieves. It does not certify.
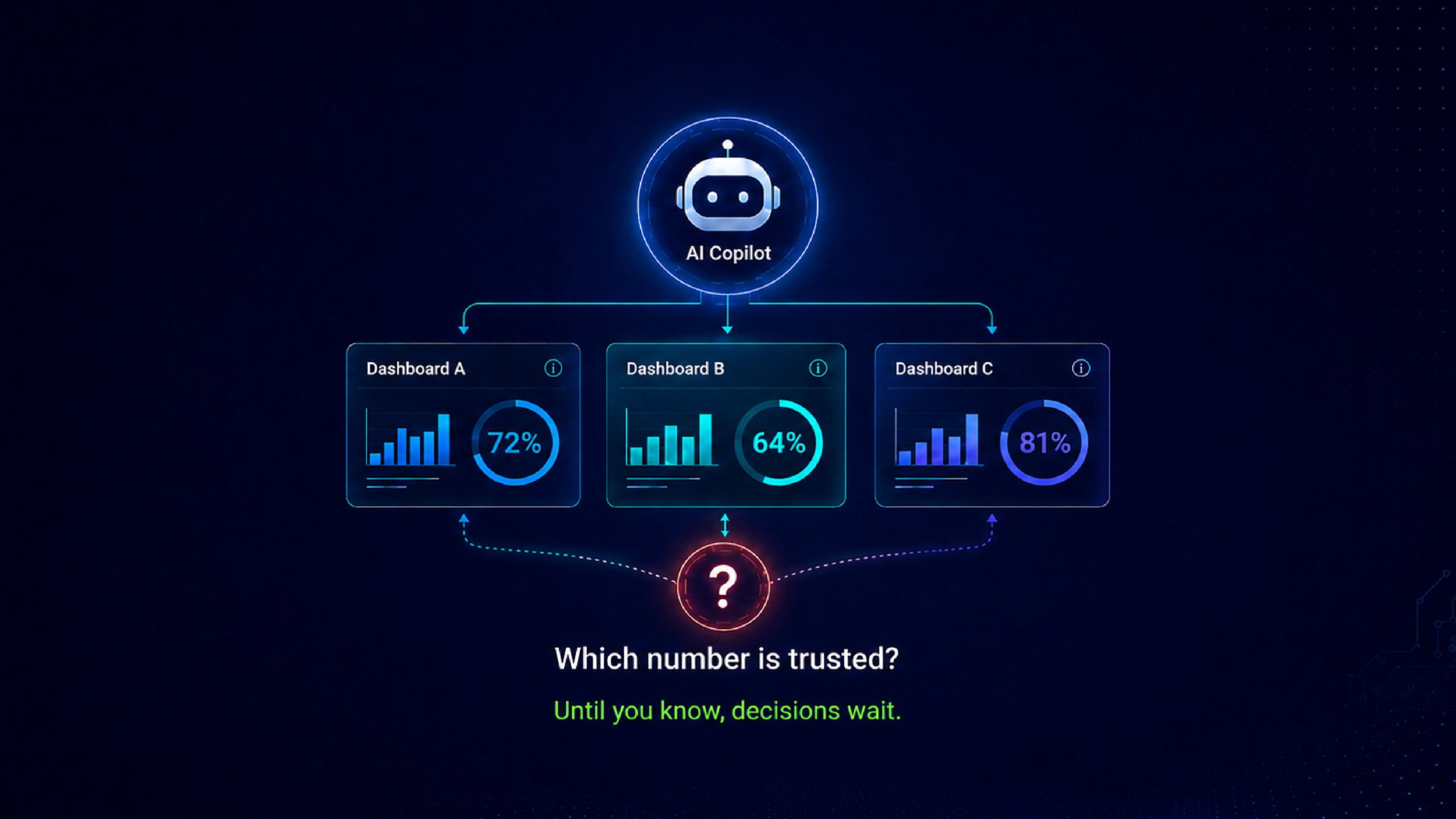
When a RAG system queries an enterprise BI estate for content related to a net revenue question, it retrieves the documents and metrics most relevant to the query according to its retrieval algorithm. What it has no mechanism to do is evaluate which of those documents represents the certified, authoritative version of net revenue and which represents a regional variant, an outdated calculation, or a shadow dashboard a business unit built independently and never reconciled with the finance team's version.
All of them are in the knowledge base. All of them are relevant to the query. All of them get retrieved. The model receives multiple conflicting definitions of the same metric with no signal about which one carries authoritative status. It synthesizes an answer from all of them. That answer is confidently delivered and wrong in ways that are hard to trace, because the retrieval step looked successful: relevant content was found and passed to the model. The failure is invisible at the retrieval layer and surfaces at the answer layer as a trust failure that gets misattributed to model behavior.
This is the same governance failure described in Enterprise AI Doesn't Hallucinate. It Reads Ungoverned Analytics, but with a more sophisticated architecture producing the same result. RAG did not solve the problem. It made the path to the ungoverned content faster.
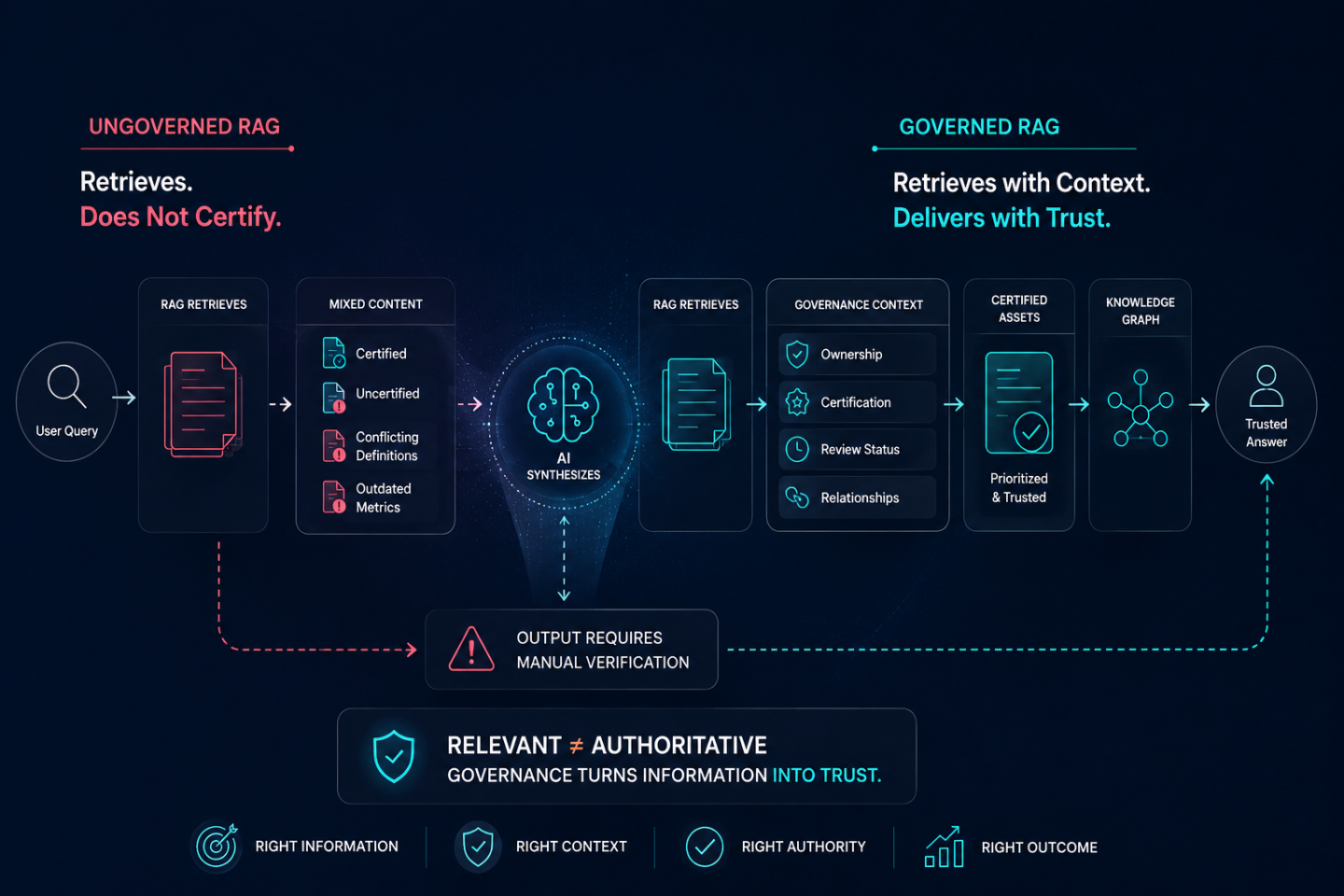
Three Specific Ways RAG Fails in Analytics Contexts
Three retrieval behaviors that are features in general knowledge contexts become failure modes when applied to enterprise analytics estates without a governance layer.
Retrieval equality across certified and uncertified assets. RAG retrieval algorithms rank results by relevance to the query, typically using semantic similarity. A certified authoritative dashboard and an uncertified regional dashboard that both discuss net revenue will rank similarly on semantic relevance grounds. The retrieval system has no native concept of certification status. Both get returned. Both enter the model's context window with equal weight. The model has no basis for distinguishing between them and no instruction to prefer one over the other.
Recency bias toward uncertified content. Many retrieval implementations weight recently modified content more heavily, on the assumption that more recent documents are more accurate. In an enterprise analytics estate, recently modified content is often a work-in-progress dashboard or a revised regional report that has not yet been reviewed, certified, or aligned with the authoritative version. The certified authoritative metric may have been stable and unchanged for months. The recency bias in retrieval surfaces the uncertified recent variant over the certified stable one. The retrieval system is working as designed. The governance context that would prevent this is absent.
No encoding of cross-metric governance relationships. RAG retrieves individual documents and metrics. It does not encode the governed relationships between metrics that multi-metric business questions require. When an AI agent answers a question that spans revenue, cost of goods, and operating margin, it needs to understand how those metrics connect in a governed hierarchy specific to this organization: which version of each is authoritative, in what sequence they should be applied, and what the certified calculation logic is at each step. The analytics knowledge graph encodes that relational structure. RAG has no equivalent. It retrieves individual assets and leaves the AI to construct the relationships through statistical inference.
What the Analytics Context Layer Provides That RAG Cannot
The analytics context layer is the governance infrastructure that RAG needs beneath it to produce trusted outputs in enterprise analytics. It addresses the three RAG failure modes directly.
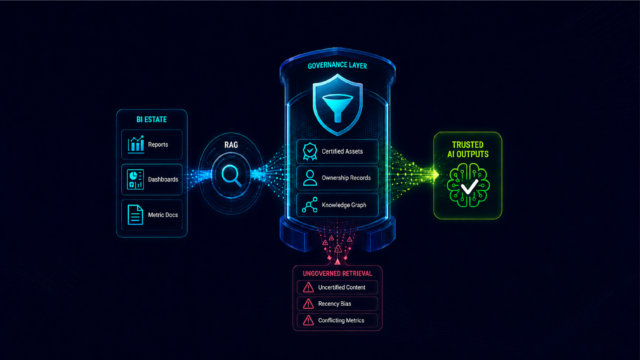
It resolves retrieval equality by providing certification metadata for every analytics asset in the estate. When the retrieval system has access to the context layer, it knows which version of each metric carries certified authoritative status, which are under review, and which are uncertified regional variants. That metadata can be used to filter retrieval results, weight certified assets preferentially, or instruct the model to apply the certified definition when conflicts exist in the retrieved context.
It resolves recency bias by providing ownership and review cycle records that establish trustworthiness independently of modification date. A certified metric that was reviewed and confirmed six months ago is more trustworthy than an uncertified metric modified yesterday. The context layer carries that distinction. RAG without the context layer cannot make it.
It resolves the relational gap by providing the knowledge graph structure that encodes how certified metrics connect in this organization's governed hierarchy. The model does not need to infer the relationships between revenue, margin, and operating performance metrics. The graph provides them as governed facts derived from the certified analytics estate. Retrieval draws on the graph to surface not just relevant individual metrics but the correct relational context for the question being asked.
Together, these three capabilities transform RAG from a capable retrieval system operating on an undifferentiated estate into a governed retrieval system operating on a certified one. The architecture is the same. What changes is what the retrieval system has to work with.
Governed Retrieval vs. Ungoverned Retrieval: The Practical Difference
The difference between governed and ungoverned RAG shows up in a single consistent pattern: governed retrieval produces answers that stakeholders can act on; ungoverned retrieval produces answers that require manual verification before anyone will act on them.
In ungoverned retrieval, the business leader asks about Q2 net revenue. The RAG system retrieves the three most semantically relevant documents from the knowledge base. All three are about net revenue. All three carry different figures. The model synthesizes a response from all three and returns a number. The CFO cannot reconcile it with the finance team's version. The commercial lead cannot reconcile it with their dashboard. The answer goes into a follow-up investigation rather than informing a decision.
In governed retrieval, the same query goes through a RAG system that has access to the analytics context layer. Atlas, ZenOptics's Analytics System of Record, has certified one version of net revenue as authoritative for commercial reporting and designated the finance team's version for P&L purposes. The context layer carries those certification records. The RAG system retrieves the certified commercial version for this query context. The model returns the certified figure. The answer matches the commercial team's expectation and is traceable to the certified source it came from.
The retrieval architecture is the same in both scenarios. The governance layer beneath it is what produces the different outcome.
What This Means for Enterprise AI Architecture Decisions
Enterprise AI teams making architecture decisions about their analytics deployments face a consistent pressure: RAG is the established pattern, the tooling is mature, and the implementation path is well-understood. The instinct is to implement RAG and then investigate governance if trust problems emerge.
The problem with that sequencing is that governance problems in analytics estates take longer to diagnose than they take to establish. An enterprise that deploys RAG against an ungoverned BI estate, experiences trust failures, investigates the retrieval configuration, adjusts the model, and still cannot resolve the inconsistency has lost quarters on a misdiagnosis before reaching the correct one: the source estate is not governed and no retrieval configuration will produce trusted outputs from it.
The correct sequence is to establish the governance layer first, then build retrieval on top of it. Nexus, ZenOptics's AI Context Layer for Analytics, is built for this architecture. Nexus automatically derives the analytics context layer from the organization's existing BI metadata through Atlas, certifies the authoritative assets, encodes the relational structure in the knowledge graph, and makes the full governance context available for retrieval systems to use. Organizations implementing this architecture see AI deployment timelines compress two to three times. The retrieval system operates on a governed foundation from the first query rather than producing trust failures that require investigation and remediation before the deployment can be trusted.
The right starting point for enterprise AI architects is not RAG configuration. It is the state of the analytics estate before retrieval is built on top of it. That estate needs to be governed before RAG can retrieve from it reliably. Analytics context engineering is the function that builds and maintains that governance. RAG is the retrieval layer that operates on top of it.
The organizations that produce trusted AI analytics outputs at scale are not the ones with the most sophisticated retrieval configurations. They are the ones that governed their analytics estates before building retrieval on top of them.
Frequently Asked Questions
What is RAG and why is it used in enterprise analytics?
Retrieval-Augmented Generation is an AI architecture pattern in which a retrieval system fetches relevant content from a connected knowledge source at query time and provides it to the AI model as context. In enterprise analytics, it is used to give AI tools access to current, organization-specific BI content: reports, dashboards, and metric definitions that postdate the model's training data or are specific to the organization. RAG is the right solution to the access problem in enterprise AI: ensuring the model can work with current, organizational content rather than approximating from training weights.
Why does RAG not solve the analytics AI trust problem on its own?
RAG retrieves the most relevant content from the connected knowledge base. It does not evaluate whether what it retrieves is certified as authoritative, whether it represents the correct version of a metric for the reporting context of the query, or how the retrieved metrics relate to each other in the organization's governance hierarchy. When an enterprise BI estate contains multiple versions of the same metric with no certification designating one as authoritative, RAG surfaces all of them with equal retrieval weight. The model synthesizes an answer from conflicting sources and returns a confidently delivered but incorrect response. The retrieval step completed successfully. The governance layer that would have prevented the conflict was absent.
What is the difference between RAG retrieval and governed retrieval?
In standard RAG retrieval, the retrieval system ranks and surfaces content by semantic relevance to the query without reference to certification status, ownership records, or governance hierarchy. In governed retrieval, the retrieval system has access to an analytics context layer that carries certification metadata for every asset in the estate. The retrieval system can filter results by certification status, weight certified assets over uncertified variants, and draw on the knowledge graph to surface the relational context that multi-metric queries require. The architecture is the same. The governance metadata beneath it is what produces different outcomes.
How does the analytics context layer work with RAG?
The analytics context layer provides three inputs that RAG needs to retrieve correctly in enterprise analytics: certification metadata that identifies which version of each metric is authoritative and for which reporting contexts, ownership and review records that establish trustworthiness independently of modification date, and the knowledge graph that encodes the governed relationships between certified metrics. RAG retrieval systems with access to these inputs can filter by certification, prefer certified assets in ranking, and surface relational context alongside individual metrics. Without the context layer, the retrieval system operates on an undifferentiated knowledge base with no mechanism for distinguishing authoritative from uncertified content.
Does this mean RAG is the wrong architecture for enterprise analytics AI?
No. RAG is the right architecture for the access problem it was designed to solve: giving AI tools access to current, organization-specific content at query time. The limitation is not in the RAG architecture. It is in deploying RAG against an ungoverned analytics estate and expecting it to produce governed outputs. RAG is a retrieval mechanism. The governance of what it retrieves is a separate requirement that the analytics context layer addresses. Both are necessary. RAG without a governance layer produces capable retrieval from an ungoverned source. RAG with a governance layer produces governed retrieval from a certified source.
What does a governed RAG implementation look like in practice?
A governed RAG implementation for enterprise analytics has four components working together. An analytics system of record, Atlas in the ZenOptics architecture, continuously inventories the BI estate and maintains certification records for every authoritative metric, report, and KPI. An analytics context layer, Nexus in the ZenOptics architecture, derives the certification metadata, ownership records, and knowledge graph structure from the certified estate. A RAG retrieval system queries the knowledge base with access to the context layer metadata, using certification status and governance hierarchy to weight retrieval results. And the AI model receives retrieved context that has been filtered and ranked against the organization's governance structure rather than by semantic similarity alone. The result is retrieval that surfaces certified, authoritative analytics content for every query, with the relational structure that multi-metric reasoning requires encoded in the knowledge graph rather than inferred by the model.
Published June 26, 2026Why RAG Is Not Enough for Enterprise Analytics AI
RAG gives AI access to your analytics estate. The analytics context layer makes that access trustworthy. Schedule a 15-minute working session with ZenOptics to review your current AI architecture and where the governance layer fits.
Schedule a 15min demo call