Every major AI readiness framework published in the last two years assesses the same things: data infrastructure quality, pipeline reliability, talent maturity, technology stack, and governance controls at the data layer. These assessments are useful. They are also incomplete in a way that consistently produces the same failure pattern in enterprise AI deployments.
When AI agents and copilots answer business questions, they do not read from the data layer. They read from the analytics estate: the reports, dashboards, KPI definitions, semantic models, and business context that sits above the data and below the AI. An enterprise that has invested in data readiness but not analytics estate readiness has a clean foundation feeding an ungoverned surface. The AI reads from the surface. If that surface is ungoverned, the outputs are inconsistent, untraceable, and untrustworthy regardless of how mature the data infrastructure beneath it is. The readiness gap that determines whether AI actually works for the business is the one almost no framework is measuring.
Why Analytics Estate Readiness Is Not the Same as Data Readiness
Data readiness programs address the infrastructure layer: data quality, schema governance, pipeline reliability, access controls, and cloud modernization. These programs are necessary prerequisites for enterprise AI. They address whether the organization's data is in a state where AI systems can access and process it.
Analytics estate readiness addresses a different layer entirely. It addresses whether the organization's analytics content is in a state where AI systems can reason from it correctly. The analytics estate is the set of reports, dashboards, certified datasets, KPI definitions, semantic models, and business context documents that the organization uses to make decisions. It is the layer that translates raw data into business meaning. AI agents and copilots operate at this layer, not at the data layer.
The distinction matters because an organization can have excellent data readiness and poor analytics estate readiness simultaneously. A clean, well-governed data lake can feed four conflicting definitions of gross margin across four separate Power BI datasets. Each dataset is built on high-quality, properly pipelined data. None of them agrees on what gross margin means. When an AI agent answers a question about margin performance, it reads from those four conflicting datasets and synthesizes an answer from all of them. The data infrastructure is not the problem. The analytics estate is.
This is the pattern that produces what looks like AI hallucination in enterprise analytics contexts but is not hallucination at all: it is accurate retrieval from an ungoverned analytics surface.
What AI Agents and Copilots Actually Read From
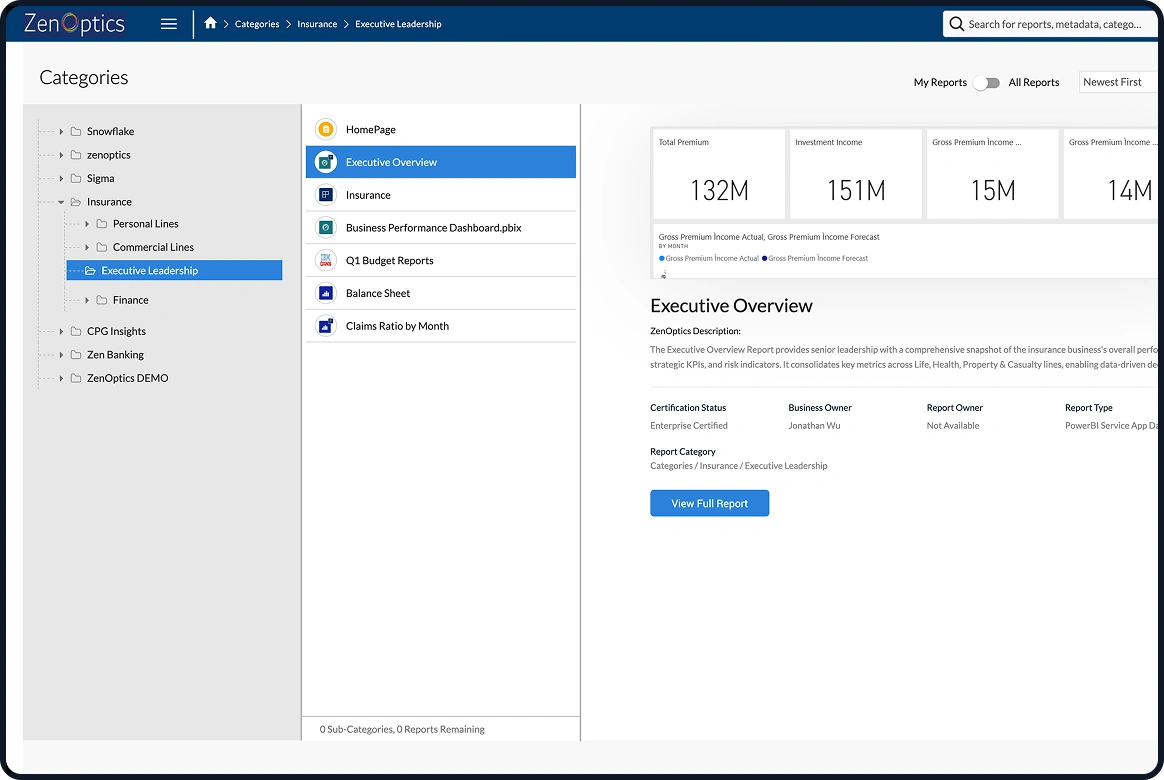
Understanding what AI agents read from is the prerequisite for fixing it. When an enterprise deploys an AI agent or copilot against its analytics environment, that agent traverses the analytics estate at query time. Depending on the deployment, it reads from some combination of: Power BI or Tableau semantic models, certified and uncertified datasets, report and dashboard metadata, business glossary entries where they exist, KPI documentation in wikis or catalogs, and in Microsoft Fabric environments, content from Excel, SharePoint, and OneLake.
The estate is the source of truth the AI reasons from. It is not a static, curated input that someone has prepared for the AI. It is the full, accumulated result of years of BI development: reports built by different teams for different purposes, datasets created for projects that ended but were never retired, KPI definitions documented by one team that contradict the definitions used by another. Every organization with a multi-year BI history has an analytics estate that reflects that accumulation.
When an AI agent reads this estate, it surfaces what it finds. It has no native mechanism to determine which version of a metric is authoritative, which dataset has been certified as the source of record for a given reporting context, or how the organization's certified metrics relate to each other when a question spans multiple KPIs. The analytics knowledge graph is the infrastructure that encodes those relationships. Without it, the AI constructs them by inference. The quality of the output reflects the quality of the estate being read.
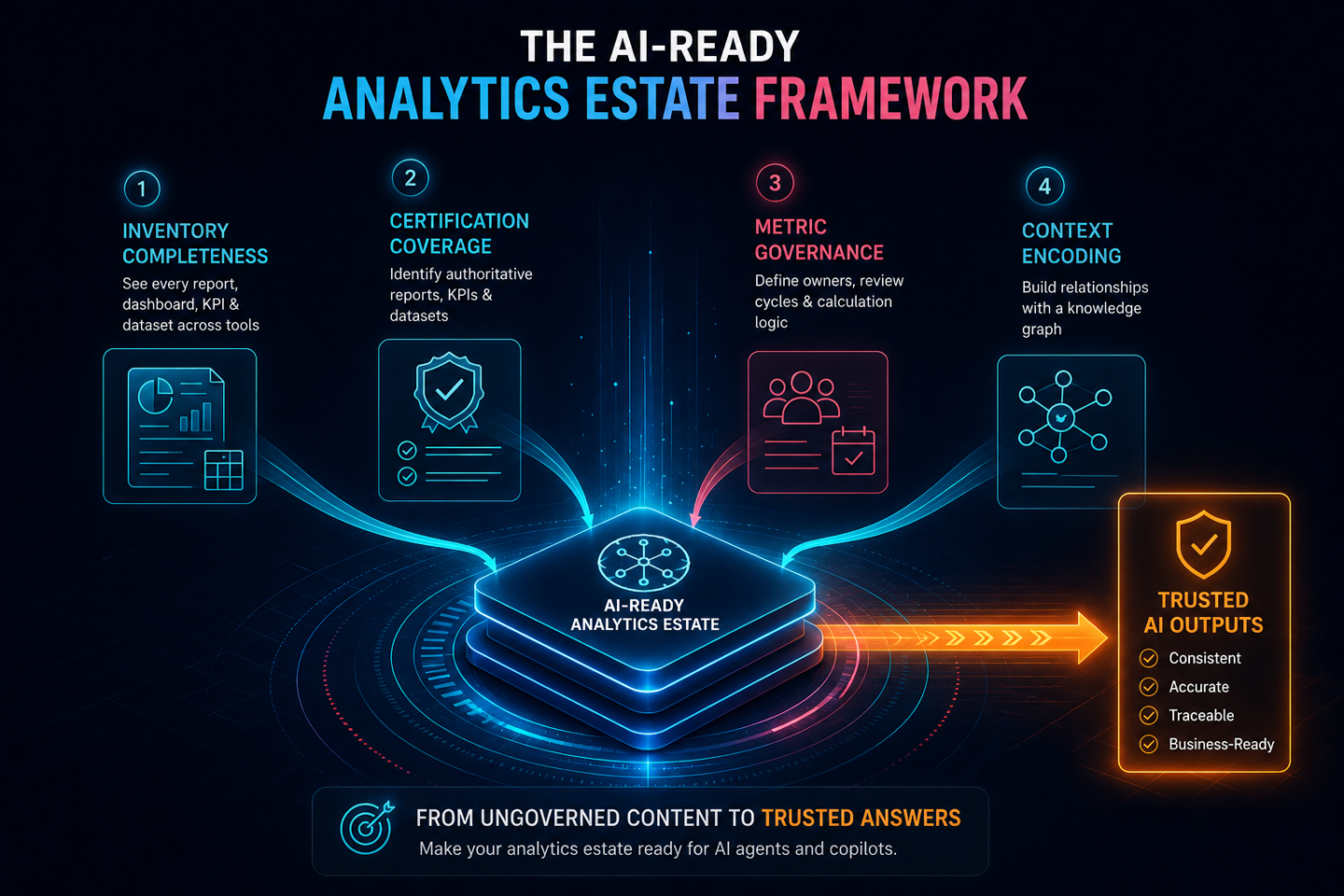
The Four Dimensions of Analytics Estate Readiness
Making the analytics estate AI-ready is a governance program, not a configuration task. It operates across four dimensions. Each dimension can be assessed independently and addressed in sequence. Together, they describe what an AI-ready analytics estate looks like and where most enterprise estates fall short.
Dimension 1: Inventory completeness. An AI-ready analytics estate requires a complete, current inventory of every active report, dashboard, KPI, and certified dataset across all BI tools the organization uses. AI cannot govern what it cannot see. Most enterprise estates are inventoried partially and separately: the Power BI catalog covers Power BI assets, the Tableau server covers Tableau workbooks, and Excel-based reports and SharePoint-hosted dashboards are not inventoried at all. Cross-tool inventory completeness is the foundation everything else depends on. Without it, the AI estate assessment is incomplete by definition.
Dimension 2: Certification coverage. Of the assets in the inventory, the key measure is the proportion that has been designated as authoritative. Certification is the process of designating a specific version of a report, dashboard, or metric definition as the organization's approved source of record for a defined reporting context. In most enterprise estates, certification coverage is low: Power BI has a certification mechanism that is partially used, other BI tools have ad hoc promotion processes, and the majority of analytics assets have no certification status at all. Uncertified assets surface in AI queries alongside certified ones. Without high certification coverage, the AI has no basis for distinguishing between the authoritative version of a metric and an outdated variant, and it does not attempt to make that distinction.
Dimension 3: Metric governance. Certification establishes which version of a metric is authoritative. Metric governance establishes who owns it, when it was last reviewed, what its calculation logic is, and which reporting contexts it governs. These records are what make certification trustworthy over time rather than a one-time designation that becomes stale. A metric certified eighteen months ago by a team that has since reorganized, with calculation logic that predates a revenue recognition policy change, is not a reliable source of truth. Metric governance is the program that maintains certification accuracy through formal ownership and review cycles. Most enterprise analytics programs have no equivalent of this at the metric layer; data governance addresses the data infrastructure, and the metric layer is ungoverned by default.
Dimension 4: Context encoding. The first three dimensions address individual assets: inventory, certification, and governance of reports, dashboards, and metrics as standalone objects. Context encoding addresses the relationships between them. When an AI agent answers a multi-metric business question, such as why operating margin contracted when revenue grew in Q3, it needs to understand how the organization's certified metrics connect: which version of revenue is authoritative for this context, how operating costs relate to gross margin in the certified calculation hierarchy, and what the approved analytical path is for this class of question. The analytics context layer encodes those relationships as governed facts the AI can follow. Without context encoding, the AI infers the relationships statistically from co-occurrence patterns in the datasets it reads. The difference between a governed relationship and a statistically inferred one is the difference between an answer grounded in the organization's business logic and an answer that approximates it.
Where Most Enterprise Estates Fall Short
Assessing enterprise analytics estates against these four dimensions produces a consistent pattern. Inventory completeness is almost always partial: BI tool catalogs exist within their own environments, cross-tool estates are not inventoried as a single coherent set of assets, and a significant proportion of actively used reports exist outside any formal catalog.
Certification coverage is low relative to the full estate. Power BI certification is the most commonly deployed mechanism, but even within Power BI, the proportion of datasets carrying certified status is typically a fraction of the total active estate. Content outside Power BI is almost never formally certified against an enterprise standard.
Metric governance is the dimension where the gap is widest. The concept of a designated metric owner with a formal review cadence and documented calculation logic is familiar from data governance programs applied to master data. Applied to the analytics metric layer, it is rare. Metrics are defined when dashboards are built and updated informally when business logic changes. Ownership is implicit rather than designated. Review cycles do not exist.
Context encoding, as a formal program, is absent in nearly all enterprise analytics estates that have not specifically invested in an analytics context layer. The relationships between certified metrics exist in subject matter experts' heads and in informal documentation. They are not encoded in a form AI agents can follow.
This is why RAG architectures deployed against ungoverned analytics estates produce the same failure pattern as direct AI queries: the retrieval system surfaces what exists, and what exists reflects all four dimensions of unreadiness. The architecture does not compensate for the estate's condition.
How Atlas, Nexus, and Maestro Build the AI-Ready Layer
ZenOptics addresses all four dimensions of analytics estate readiness through three connected products, each targeting a specific layer of the problem.
Atlas, ZenOptics's Analytics System of Record, addresses inventory completeness and metric governance. Atlas continuously inventories the analytics estate across Power BI, Tableau, Fabric, and connected BI tools, maintaining a living record of every active report, dashboard, KPI, and dataset in the environment. It establishes and maintains certification records, ownership designations, and review cycle tracking for every authoritative analytics asset. The estate inventory is not a one-time audit: Atlas keeps it current as assets are added, modified, retired, or recertified. The result is a governed, maintained record of what the analytics estate contains and what within it has been designated as authoritative.
Nexus, ZenOptics's AI Context Layer for Analytics, addresses certification coverage and context encoding. Nexus derives the analytics knowledge graph from the certified estate Atlas governs, encoding the relationships between certified metrics in a machine-readable structure AI agents can follow. It provides the certification metadata and cross-metric relational context that transforms AI queries from inference operations on an ungoverned estate into governed retrieval from a certified one. When an AI agent queries the estate with Nexus providing the context layer, it receives not just the relevant metrics but the governance records that establish which version is authoritative and how it connects to the other certified metrics the question requires.
Maestro, ZenOptics's AI-Driven Business Processes layer, is the AI agent layer that operates on top of the governed estate Atlas and Nexus produce. Maestro's AI agents perform reliably because the estate beneath them has been made AI-ready. The AI agent quality is a function of the estate quality. Maestro is built on the premise that AI agents operating on a governed analytics estate produce different outcomes than AI agents operating on an ungoverned one. That premise is what the first four sections of this post establish.
What Changes When the Analytics Estate Is AI-Ready
The outcome of analytics estate readiness is not a different AI model. It is a different surface for the same AI to read from. This distinction matters because it explains why prompt engineering, model fine-tuning, and retrieval configuration improvements produce limited results when the underlying estate is ungoverned: the problem is not the AI, it is the estate.
In the ungoverned scenario, a business leader asks an AI agent about Q3 operating margin. The agent traverses the estate and finds three definitions of operating margin across four datasets, two of which are certified in Power BI and two of which are uncertified project models that were never retired. It synthesizes across all four, returns a figure, and surfaces the certified Power BI dataset as the primary source. The figure does not match the finance team's Q3 close number. No one can reconcile it without investigating which datasets the agent weighted and why. The follow-up investigation takes longer than the original question would have taken to answer manually.
In the governed scenario, the same AI agent queries the estate with Atlas's inventory and certification records and Nexus's knowledge graph context available at query time. Atlas has certified one version of operating margin as authoritative for Q3 close reporting, with the finance team as designated owner and a review date from last month confirming the calculation reflects the current cost allocation policy. Nexus has encoded operating margin's relationship to the gross margin and SG&A metrics the agent needs for the full answer. The agent surfaces the certified Q3 close version, returns the correct figure, and the reasoning path is traceable back to the certified source records. The answer matches the finance team's close number because it came from the same certified source. It is consistent across every team member who asks the same question and auditable at the metric level.
No prompt engineering produced this outcome. No model change produced it. The estate change produced it.
Frequently Asked Questions
What is the difference between data readiness and analytics estate readiness?
Data readiness describes the state of an organization's data infrastructure: data quality, pipeline reliability, schema governance, and access controls at the data layer. Analytics estate readiness describes the state of the analytics content that AI agents actually read from: the reports, dashboards, KPI definitions, semantic models, and business context documents that translate data into business meaning. An organization can have excellent data readiness and poor analytics estate readiness simultaneously. Data readiness addresses the foundation. Analytics estate readiness addresses the surface AI agents operate on.
What does an AI-ready analytics estate look like in practice?
An AI-ready analytics estate has four properties. The full estate across all BI tools is inventoried in a single, continuously maintained record. Every authoritative metric, report, and dashboard has been designated as certified, with a designated owner, a last-reviewed date, and documented calculation logic. Certification coverage extends across the full estate, not just within a single BI tool's catalog. And the relationships between certified metrics are encoded in a machine-readable knowledge graph AI agents can follow for multi-metric questions. Organizations with these four properties in place see consistent, traceable AI outputs across query types and reporting contexts.
Does building an AI-ready analytics estate require replacing existing BI tools?
No. Analytics estate readiness operates above the BI tool layer, not within it. Atlas inventories and certifies assets across Power BI, Tableau, Fabric, and connected BI environments without replacing them. Nexus provides the context layer above the tools that AI agents read from. The existing BI estate remains in place; the analytics context layer is built on top of it to make the estate AI-readable. The investment is in governance and context, not in tool migration.
How long does it take to make an analytics estate AI-ready?
The timeline depends primarily on the size of the estate, the current state of certification coverage, and whether metric ownership programs exist. Most enterprise AI deployments that attempt to address analytics estate readiness after encountering trust failures lose two to three quarters to misdiagnosis before identifying the estate as the source. Organizations that address estate readiness before AI deployment typically compress that timeline significantly. Atlas's continuous inventory approach means the estate does not need to be governed all at once: the highest-priority metrics and reports can be certified first, creating a governed core the AI operates from while the broader estate is brought into compliance.
What is the Analytics Estate Assessment Scorecard and how do I use it?
The Analytics Estate Assessment Scorecard is a structured evaluation tool that maps an organization's analytics estate against the four dimensions of AI readiness: inventory completeness, certification coverage, metric governance, and context encoding. It produces a score across each dimension and identifies the specific gaps most likely to produce AI trust failures in the current environment. The Scorecard is available as a gated resource through ZenOptics and takes approximately 15 minutes to complete for a BI leader or CDO with knowledge of the current analytics environment.
Where do most enterprises fall short on analytics estate readiness?
Metric governance is consistently the widest gap. Most enterprises have some form of inventory mechanism within individual BI tools, and Power BI certification is increasingly deployed, but the concept of a formally designated metric owner with a documented review cadence and explicit calculation logic at the metric layer is uncommon. Context encoding is absent in virtually all enterprise estates that have not specifically invested in an analytics context layer: the relationships between certified metrics exist informally but are not encoded in a machine-readable structure AI can follow. These two dimensions produce the most severe AI trust failures because they affect every multi-metric question an AI agent is asked.
Published June 29, 2026Your Analytics Estate Isn't AI Ready. Here's How to Fix It.
The gap between AI ambition and AI results in enterprise analytics is almost always an estate readiness problem, not a model problem. ZenOptics's Analytics Estate Assessment Scorecard helps you identify exactly where your estate stands across all four dimensions. Schedule a 15-minute working session to walk through it.
Schedule a 15min demo call